
In this short tutorial we will discuss how we can harness the powers of Large Language Models (LLMs) without buying expensive laptops, computers and without burning a hole in your pocket.
Ollama makes it possible to leverage powerful large language models (LLMs) like mistral, llama3 etc. without needing a powerful expensive compute machine.
Google Colab’s provides a cloud environment perfectly suited for running these resource-intensive models. This guide meticulously details setting up and running Ollama on the free version of Google Colab, allowing you to explore the capabilities of LLMs without burning a hole in your pocket.
Steps needed to get Ollama up and running on Google Colab
Without wasting much time lets dive into the steps we need to perform to harness power of LLMs.
Step 1: Install Packages
Installing and load modules in google colab notebook
!pip install colab-xterm #this will install colab-xterm
%load_ext colabxterm
Step 2: Open terminal
After installing now we need to open terminal to access command line on google colab
%xtermA terminal will open and you will see something similar in your notebook

Step 3: Install ollama
Run below command on the terminal to install Ollama
curl -fsSL https://ollama.com/install.sh | sh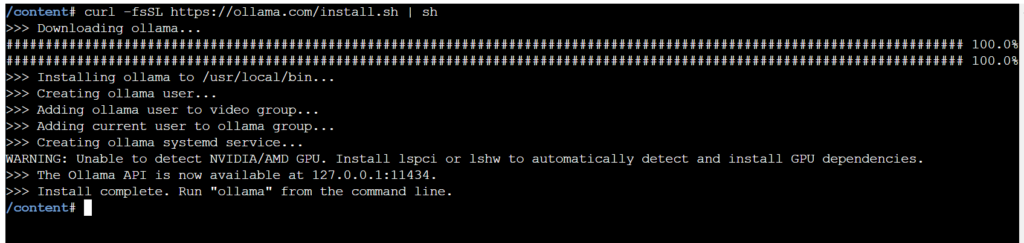
Step 4: Pull the desired model
Ollama supports quiet a few models and a list of these can be found on there official website at below address: https://ollama.com/library Please type below command in the terminal
ollama serve & ollama pull llama3
Step 5: Integrating Ollama with Langchain
Via Langchain we can integrate LLMs into applications. Please follow below article to have better understanding of Langchain applications
!pip install langchain_communityStep 6: Set environment variable
There are many fancy ways to use the above setup either locally or on cloud. The easiest among them is to use Ollama setup via the same colab notebook. To do this run below command:
!export OLLAMA_HOST=127.0.0.1:11435Step 7: Get response from Model
To test the above setup, we will initialize the model and invoke a very basic response. To do so type below code in you notebook
!export OLLAMA_HOST=127.0.0.1:11435
!pip install langchain_community
# Import Ollama module from Langchain
from langchain_community.llms import Ollama
# Initialize an instance of the Ollama model
llm = Ollama(model="llama3")
# Invoke the model to generate responses
response = llm.invoke("Tell me a joke")
print(response)
Execute above code and hurray we can see the response from the LLM

# Invoke the model to generate responses
response = llm.invoke("Tell me a joke about LLMs")
print(response)
Why did the Large Language Model go to therapy?
Because it was struggling with its "context" and was feeling a little "disjointed"!
(Sorry, I know it's a bit of a "stretch", but I hope it made you smile!)
Have fun. Keep watching this space for more such articles.